


A Comprehensive and Holistic Approach to Digital Banking to Get Closer to the Customer
A Comprehensive and Holistic Approach to Digital Banking to Get Closer to the Customer Press

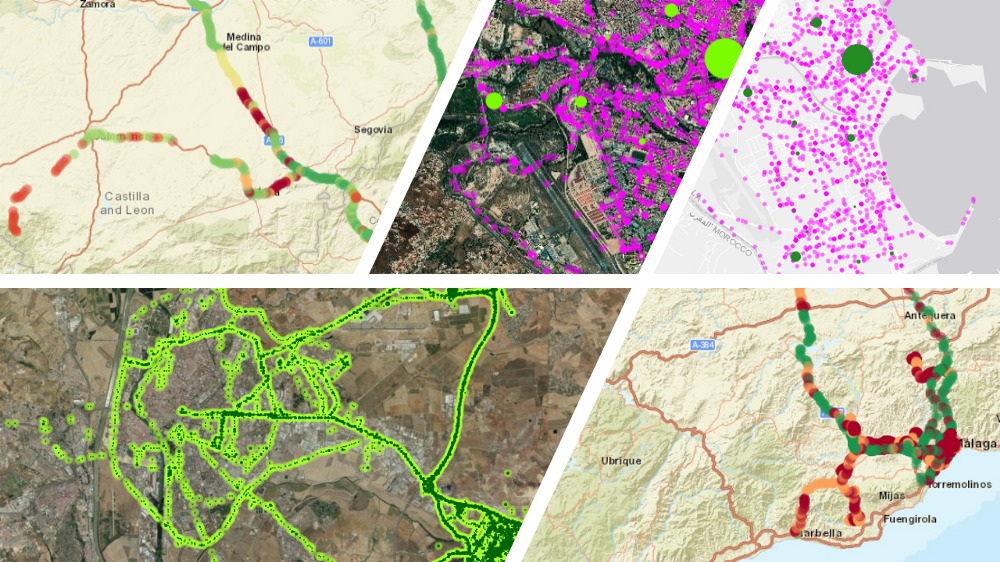
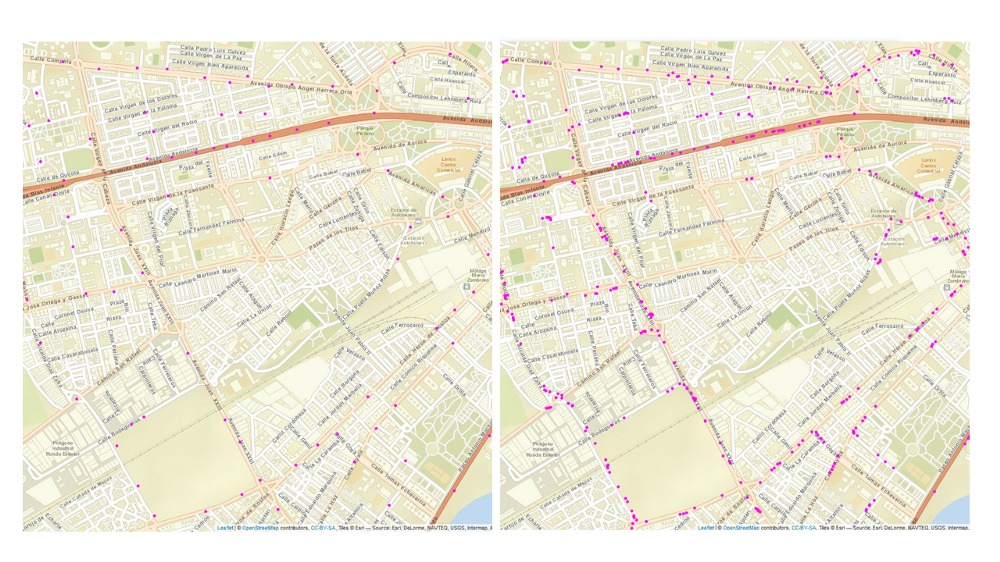
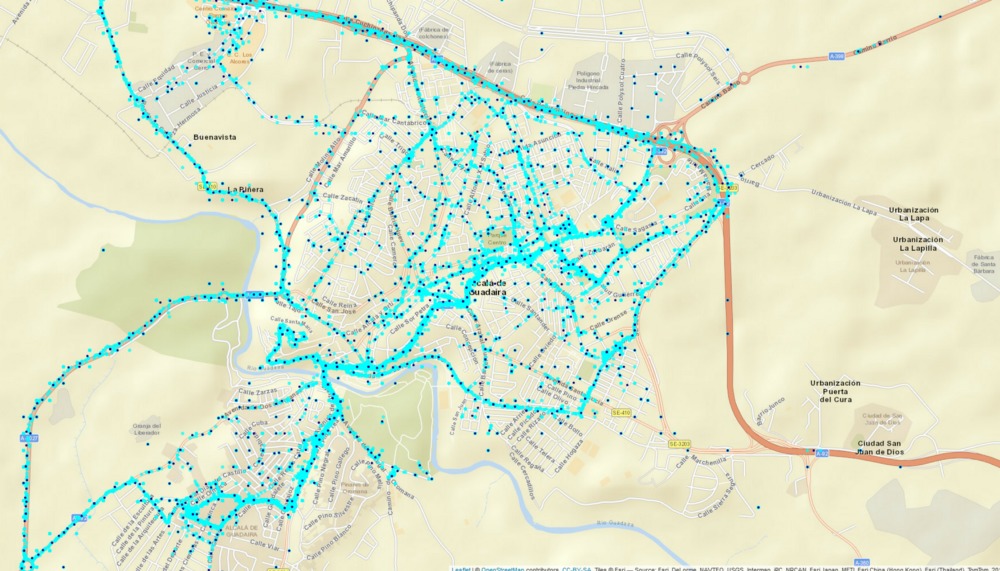
The customer lifecycle in a digital environment
The customer lifecycle in a digital environment Press ReleaseMadrid, 11th May 2021The digital customer lifecycle

The dilemma for the banking industry: current customers and the future
The dilemma for the banking industry: current customers and the future GDS Modellica The banking